

Recurrent neural networks (RNNs) are a type of neural network that are very effective at modeling sequential data. However, RNNs have a major problem known as the vanishing gradient problem. This problem occurs when the RNN is trying to learn long-term dependencies. The vanishing gradient problem occurs because the gradients of the error with respect to the weights in the RNN diminish exponentially as they are propagated back through time. This problem was solved by Long Short-Term Memory (LSTM) networks. LSTM networks are a type of RNN that uses a special type of cell known as a memory cell. Memory cells have the ability to remember information for long periods of time. This allows LSTM networks to effectively learn long-term dependencies.
What Kind Of Problem Does Rnn Solve?

RNNs are a type of artificial neural network that are well-suited to processing sequential data, such as text, audio, or video. RNNs can remember long-term dependencies, which makes them ideal for tasks such as language translation orspeech recognition.
CNNs and RNNs excel at analyzing images and text, respectively. In the following demonstration, you can see this.
In the first demonstration, handwritten digits are recognized by a CNN. This task is better suited to CNN because it employs a layout that allows it to process images more efficiently. The RNN is better suited for text or video analysis, as demonstrated in the second demonstration. This is due to RNN’s ability to handle sequential data, accept current input data, and receive previous input data.
RNNs are better suited for text or video analysis than CNNs, which are better suited to image analysis.
What Kind Of Data Rnn Specializes For?
A recurrent neural network (RNN) is a type of artificial neural network in which sequential data or time series are used.
Advantages Of Rnns For Sentiment Analysis
RNNs provide a number of advantages over other machine learning methods when it comes to sentiment analysis. They have the necessary skills to recognize patterns in large data sets in order to be effective in tasks like sentiment analysis. Furthermore, they are capable of learning abstract patterns over time, which is essential for tasks such as sentiment analysis, which necessitates knowing the sentiment of multiple items over time. Finally, RNNs are capable of handling long sequences of data, which is useful in tasks such as sentiment analysis, which must understand sentiment over time for a variety of reasons.
What Kind Of Problems Does Rnn Lstm And Gru Solve?
The exploding and vanishing gradient problem is solved by GRU networks by using this LSTM technique. The LSTM or GRU networks can be used by nearly every state of the art RNN SOTA model to predict outcomes. This technology is used for speech recognition, text generation, caption generation, and so on.
Lstm Vs. Gru: Which Is Better For Long-term Memory Applications?
In the end, LSTM is the better long-term memory option, whereas GRU is the better fast-term memory option.
What Problem Of The Rnn Does Lstm Solve?
Using Long-Term Memory (LSTM) is one method. LSTM networks are one option for addressing the issue of gradient vanish, as well as long term dependency on RNN.
The Vanishing Gradient Problem
This limitation, in many cases, causes the network to perform poorly because it causes instability and a lack of generalization. Several approaches have been proposed in recent years to address the vanishing gradient issue, but the results have been mixed.
Several researchers have proposed a new approach that allows gradients to spread in the absence of a connection. Other techniques for estimating the gradient include the use of a differentiable Boltzmann machine (DBM).
Neither of these methods can be perfect, but they do have some drawbacks. Finding a solution to the vanishing gradient problem may be difficult.
What Is The Major Benefit Of Lstm Network Over Rnn?

There is an LSTM network to combat the RNN’s vanishing gradient or long-term dependence issue. Gradient vanishing occurs when a neural network’s information is lost over time as connections recur. As a result, LSTM is able to deal with the problem of network vanishing by ignoring useless data/information.
Because of their ability to memorize sequences of data, LSTMs are frequently combined with other recurrent neural networks (RNNs), which are better at learning short-term dependencies.
The LSTMs are more effective at learning long-term dependencies than the RNNs, but the RNNs are more effective at learning short-term dependencies. RNNs’ efficiency is also superior, allowing them to operate on less computing power.
Long-term dependencies are beneficial to learning LSTMs, but they are not always as effective as RNNs in short-term dependency tasks.
Is Lstm Always Better Than Rnn?
Because it is more efficient, it is commonly used rather than vanilla (or standard) RNNs in practice.
Lstm Is The Best Algorithm For Time Series Forecasting
Because of its high precision and speed, LSTM is one of the most powerful recurrent network algorithms available. As a result, it is the best algorithm for time series forecasting, which is important for business applications.
What Is The Main Advantage Of Lstms?
LSTMs provide us with a wide range of parameters, including learning rates and input and output biases. As a result, the necessary adjustments do not have to be made. Because LSTMs are simpler than back-Propagation Through Time (BPLT) to update each weight, they are one of the most cost-effective methods for updating them.
The Power Of Lstms
Their ability to recall the past and predict the future makes them a powerful tool for sequence prediction. As a result, they excel at a wide range of tasks, including machine translation and speech recognition.
They can also be used for a variety of other tasks, including classification and text recognition, in addition to being versatile.
How Does Lstm Overcome The Limitations Of Rnn?
The network is encouraged to perform desired behavior from the error by continuously updating gradient gates on every time step of the learning process using the LSTM solution, which employs a unique additive gradient structure that includes direct access to the forget gate’s activations.
Lstm Solves The Problem Of
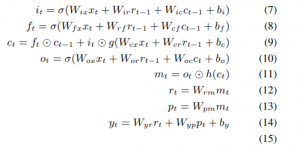
The LSTM was developed to address the vanishing gradient issue. This is achieved by using the Constant Error Carousel (CEC), as illustrated in the diagram below (from Greff et al.).
Lstms: A Tool For Solving The Vanishing Gradient Problem
A LSTM is a powerful tool for solving the vanishing gradient problem that can be difficult to train using a traditional RNN. The LSTM is well suited for predicting the duration of an event in a time series due to the lag between important events, so it can be used to classify, process, and predict. Because of its limitations, traditional RNNs may encounter the vanishing gradient problem when training LSTMs. Finally, LSTMt cannot solve the problem of exploding gradient surfaces; the gradient’s overall composition could still explode, so we prefer to move in the direction of the gradient rather than move in a large magnitude direction because a gradient has some magnitude and direction.
Recurrent Neural Network Solved Example
A recurrent neural network (RNN) is a neural network that performs well on tasks that require the network to remember previous inputs. This is due to the fact that an RNN can maintain an internal state that allows it to remember previous inputs. For example, an RNN could be used to predict the next word in a sentence, based on the previous words in the sentence.
On The Difficulty Of Training Recurrent Neural Networks
Recurrent neural networks (RNNs) are a type of artificial neural network where connections between nodes form a directed graph along a temporal sequence. This allows it to exhibit temporal dynamic behavior. Deriving their name from the Latin word recurrent, RNNs can be used to create models that take as input a sequence of vectors and output a single vector, a sequence of vectors, or a probability distribution over a set of classes.
Why Are Recurrent Neural Networks Hard To Train?
When recurrent neural networks are not fedforward neural networks, they are difficult to train. Signals in feedforward neural networks are limited in their movement. From an input layer to various hidden layers and back again, the signal travels from a given system input layer to the given output layer.
Rnn: Not The Best For Unsupervised Learning, But Can Be Trained As A Supervised Learning Algorithm
RNN’s speed and processing time make it unsuitable for unsupervised learning. RNN, on the other hand, can be trained as a supervised learning algorithm by using a pre-trained model.
What Are The Issues Faced While Training In Recurrent Neural Networks?
Several well-known problems with recurrent neural networks, including the vanishing and exploding gradient, are described in Bengio et al.
The Pros And Cons Of Training Employees In Multiple Locations
Geographic Limitations of the World Many businesses now employ people in multiple countries, and the task of training them in different locations can be difficult.
The cost of living has risen. Training can be costly, especially for new hires.
The language barrier is caused by factors such as: Many employers have employees who need to be fluent in various languages, which can be a challenge.
There are translation issues. Many businesses require translations of their training materials in various languages, which can be time-consuming and costly.
For more information, please visit the following website: There are now a lot of businesses that want to deliver training online, and it can be a difficult task.
What Are The Two Main Difficulties When Training Rnns?
Bengio et al. (1994) present two widely accepted problems with properly training Recurrent Neural Networks: the vanishing gradient and the exploding gradient.
The Many Potential Applications Of Recurrent Neural Networks
Despite these challenges, recurrent neural networks can still be used for machine learning, sentiment analysis, and language recognition. We expect researchers to make progress in the coming months in overcoming network problems, which will allow for more adoption.
What Is The Problem Of Recurrent Neural Network?
The absence of gradient vanishers is one of the RNN’s greatest challenges. As the gradient becomes too small, the information that can be carried out in the RNN is no longer carried out, and the parameter updates become insignificant. When you’re learning long data sequences, you can’t do it easily.
Rnns: The Neural Networks With A Memory
The neural network’s internal memory is one of the reasons why it can remember characters. It generates output and copies it back into the network after it has been re-generated. This process is repeated until the network has determined the characters.
Problems With Lstm
There are a few potential problems with using LSTMs. First, LSTMs can be computationally intensive, and therefore may not be practical for large-scale applications. Second, LSTMs may not be able to accurately model long-term dependencies, which can limit their usefulness for certain tasks. Finally, LSTMs may be subject to the vanishing gradient problem, whereby the gradients of the error signal diminish over time, making it difficult to learn from long sequences.
Why Lstm Is Not Good For Time Series?
The LSTM necessitates more computation than any other recurrent neural network. The fact that it has more parameters in order to forecast demand is one of its features.
Are Lstms Outdated?
It should come as no surprise that LSTM layers are still essential to a time-series deep learning model. Furthermore, they do not interfere with the Attention mechanism. Furthermore, the two components can be combined in order to improve model efficiency by using an Attention component.
Types Of Recurrent Neural Network
A recurrent neural network (RNN) is a type of neural network that is used for modeling sequential data. RNNs are different from other types of neural networks because they have a feedback loop, which allows them to remember information from previous iterations. This makes RNNs well-suited for tasks such as language modeling and machine translation, where understanding the context of a word is important.
The Three Main Types Of Recurrent Neural Networks
There are three types of recurrent neural networks: simple RNNs, long-term memory neural networks, and gate-based neural networks. RNNs are the most basic types of recurrent neural networks. The system is made up of a series of interconnected nodes, each with a specific output value. It can learn how to recognize patterns by adapting its weights, which are stored in its memory. Long-term memory neural networks are a more advanced variant of recurrent neural networks. The system can forecast the next sequence by recalling a previous sequence of input values. Each of the network’s nodes can remember a sequence of input values over time, which is a part of the network. Neural networks based on gate cells are more advanced in speech recognition and natural language processing than conventional neural networks. Each node in a network can generate one or more output values based on a specific set of input values.